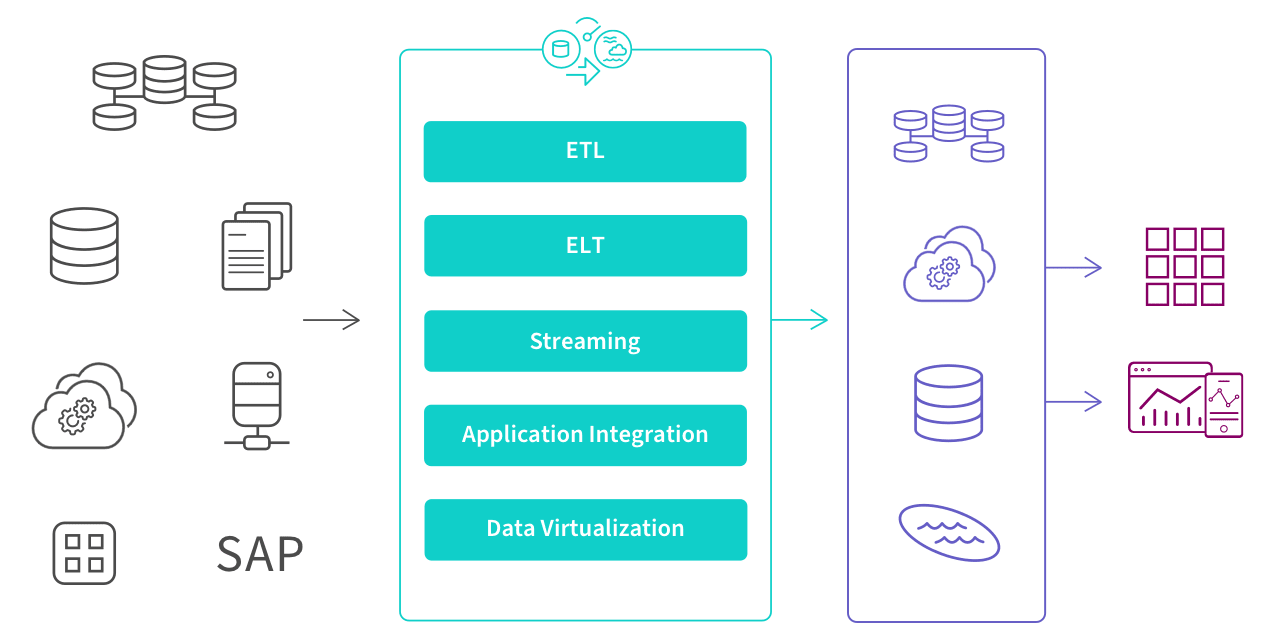
Five Approaches
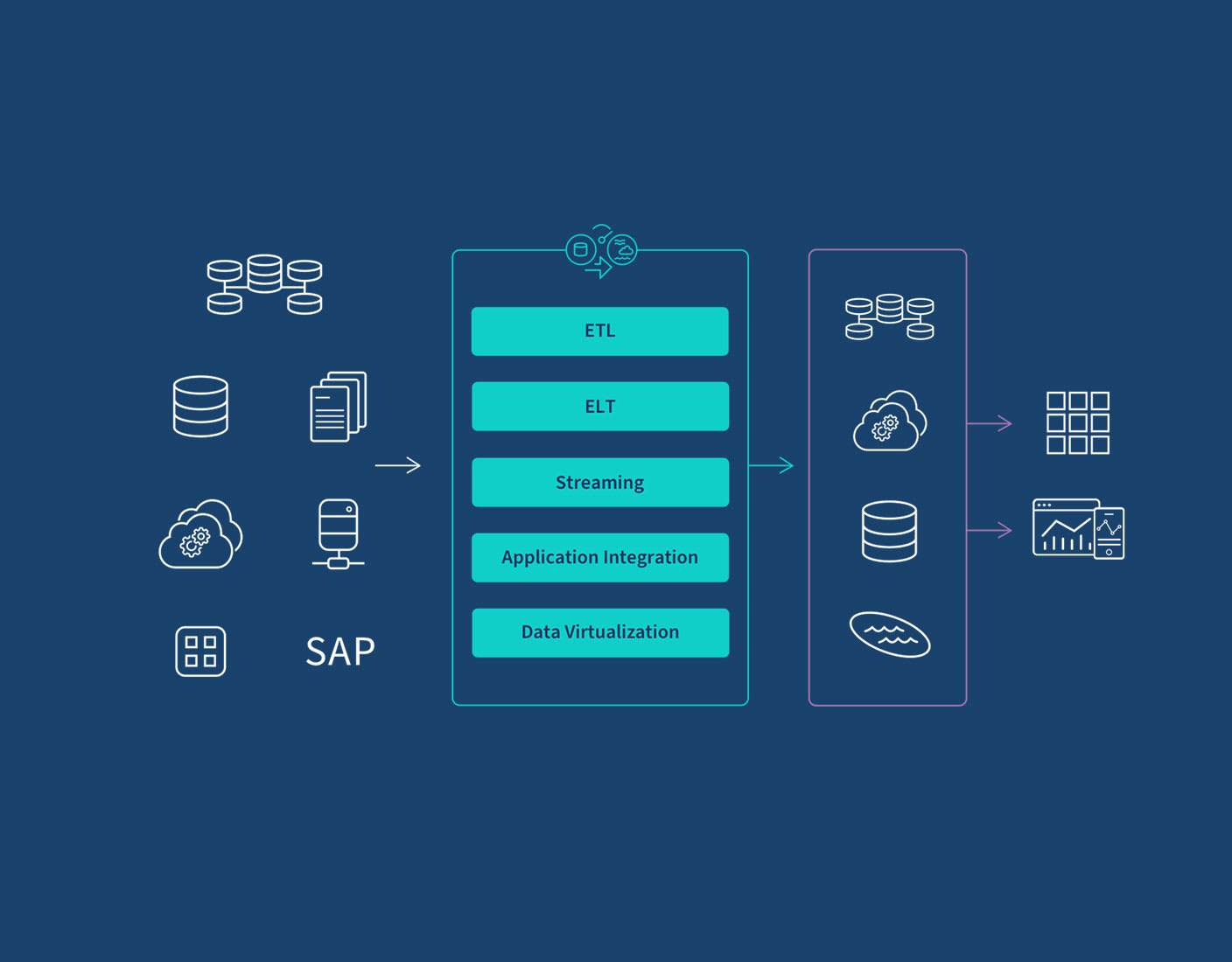
There are five different approaches, or patterns, to execute data integration: ETL, ELT, streaming, application integration (API) and data virtualization. To implement these processes, data engineers, architects and developers can either manually code an architecture using SQL or, more often, they set up and manage a data integration tool, which streamlines development and automates the system.
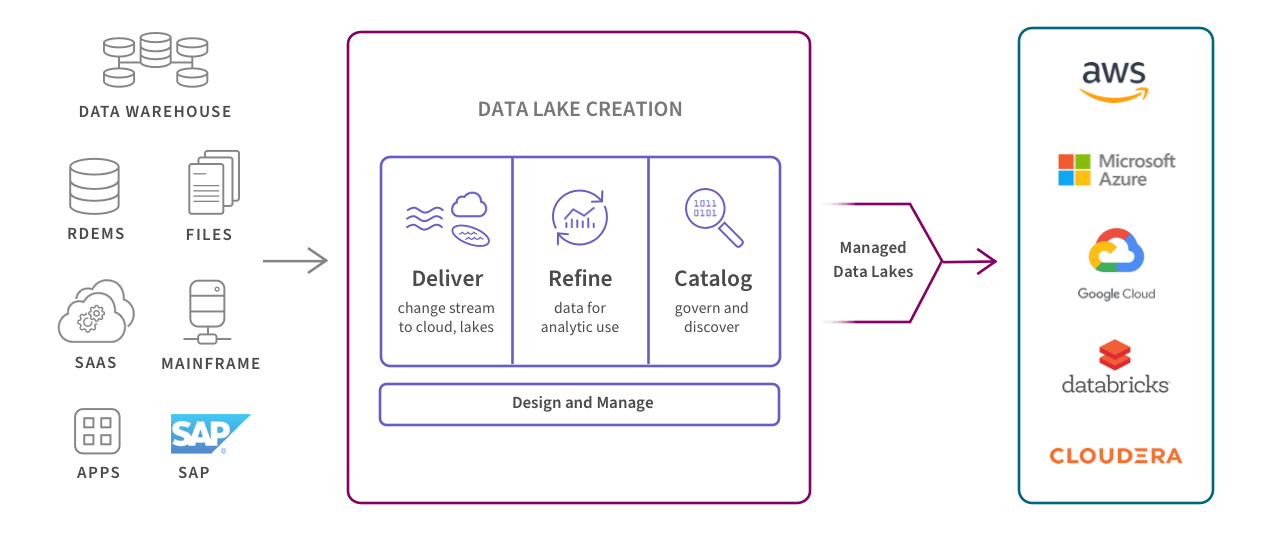
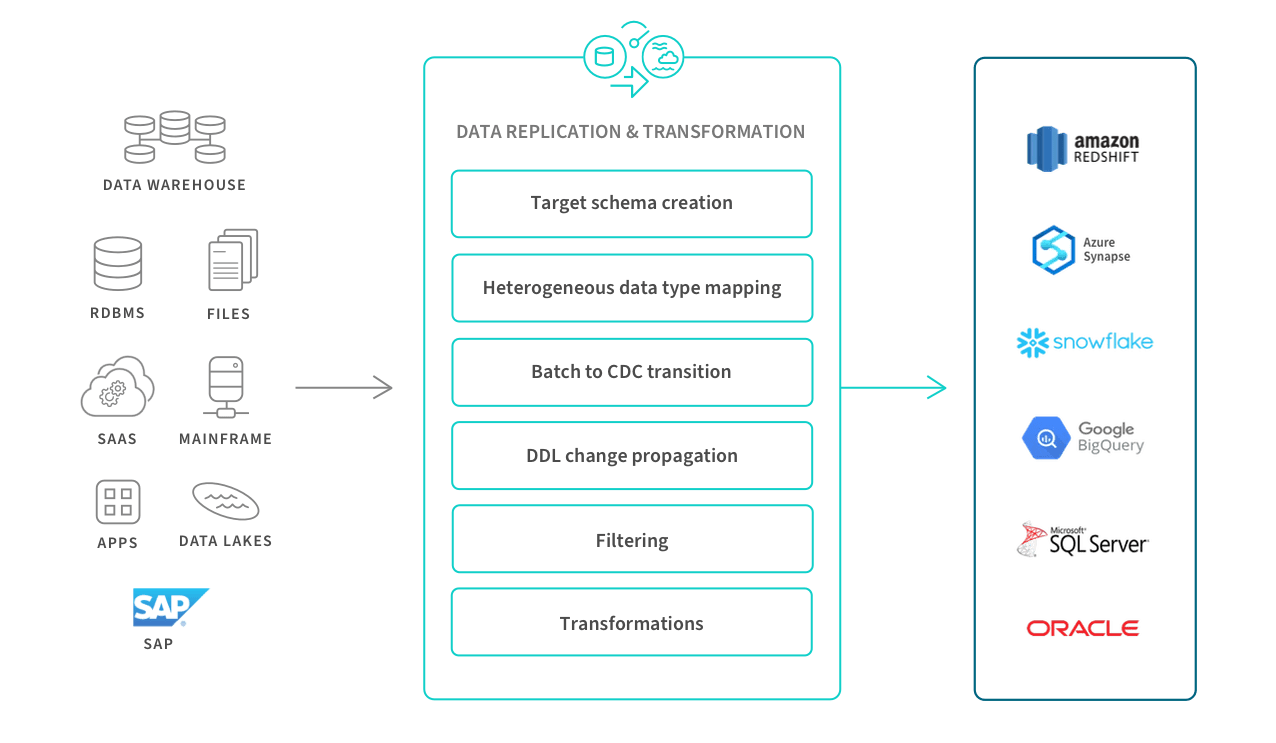
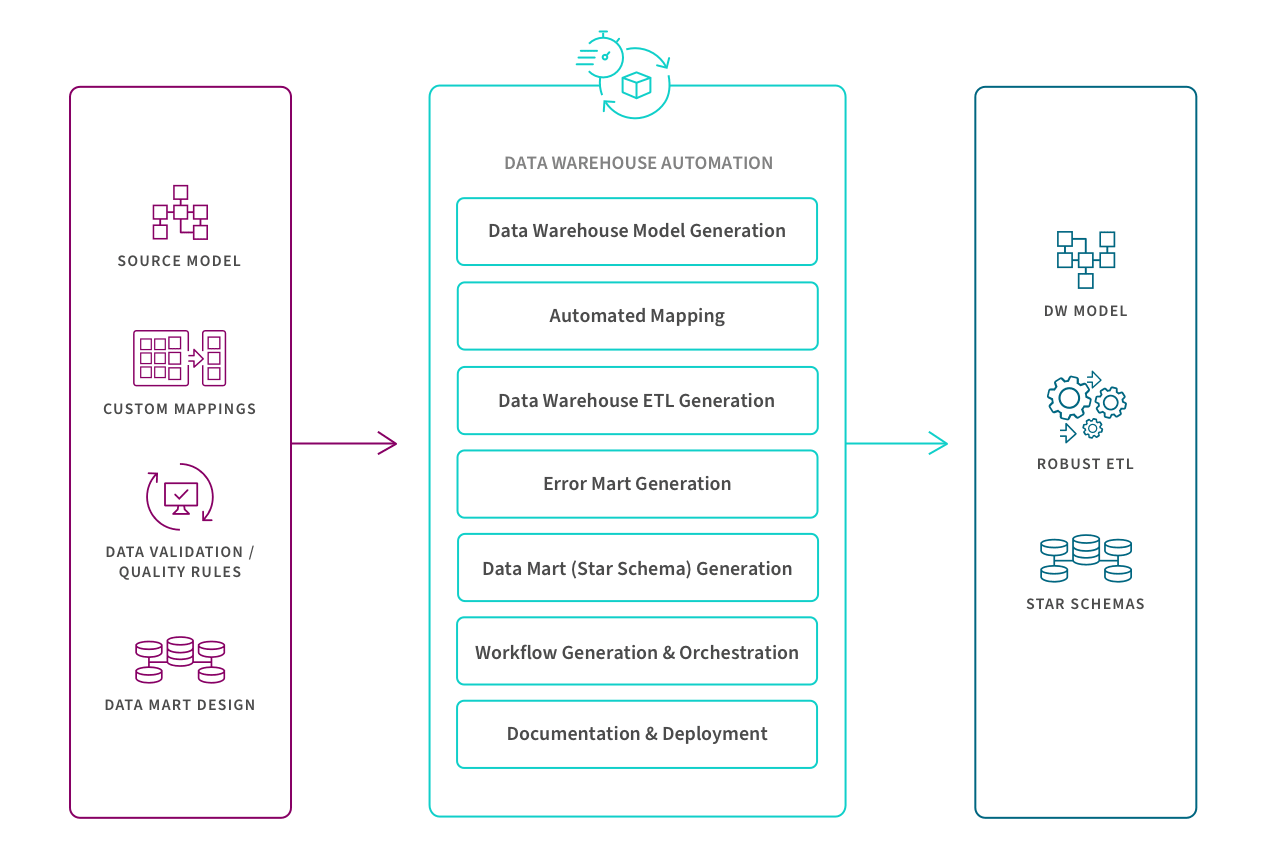
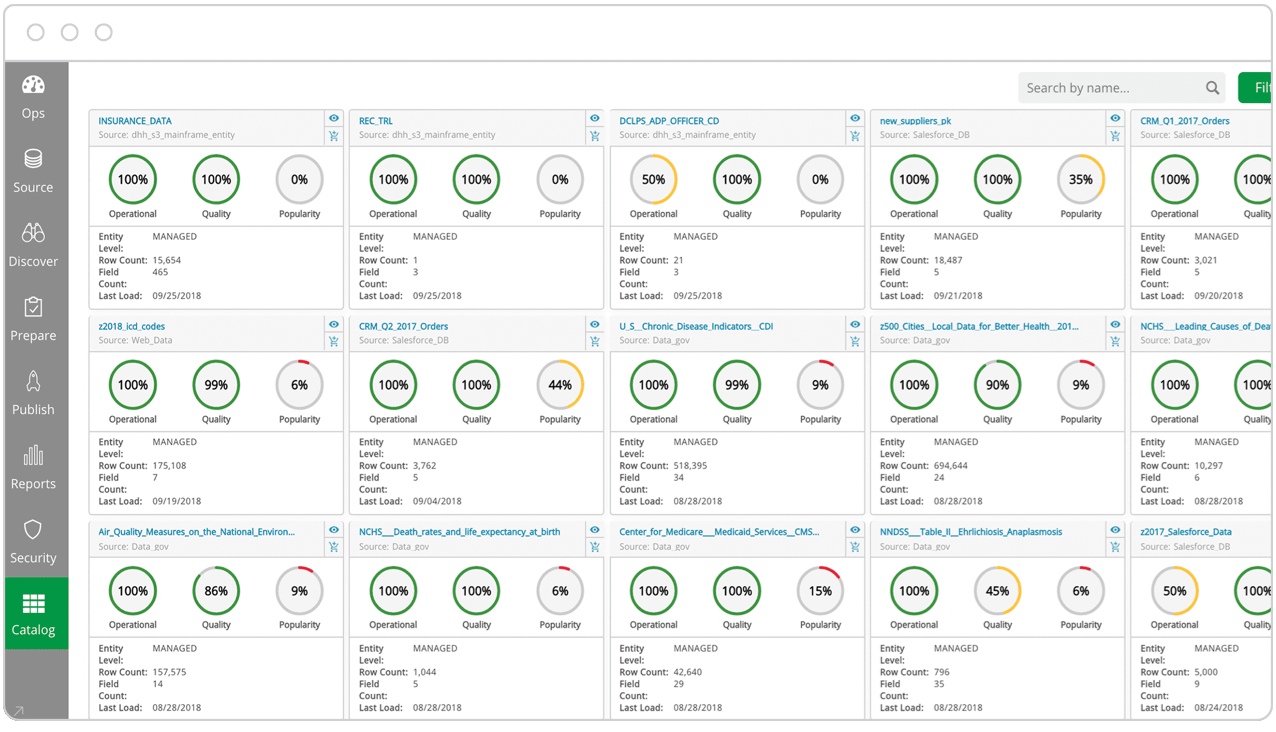
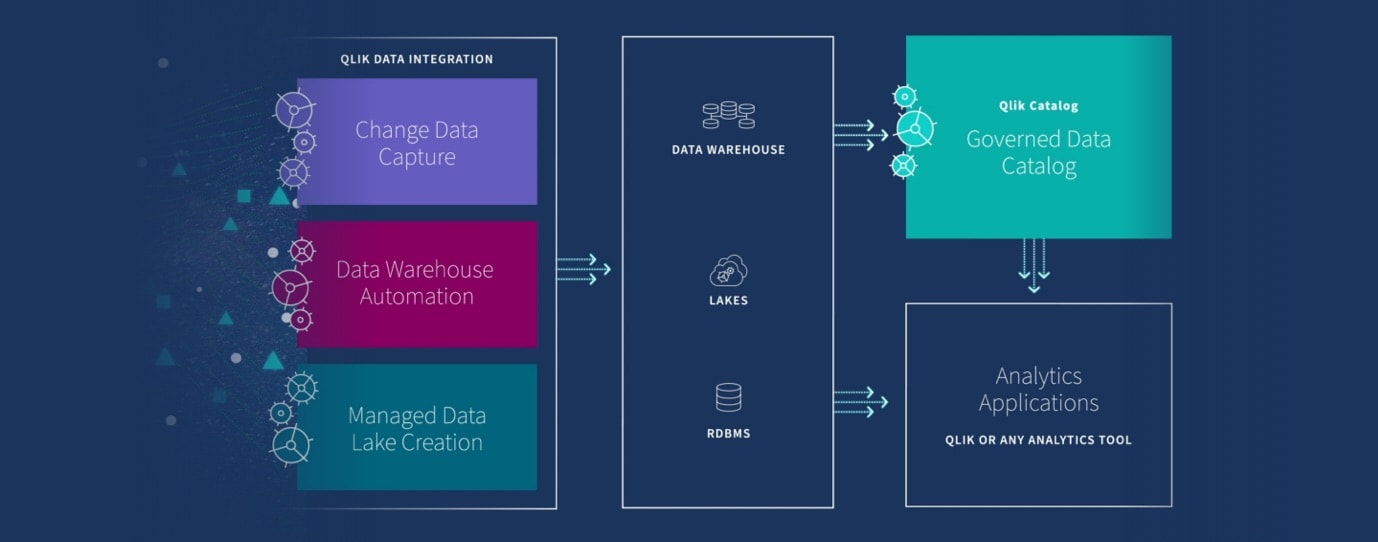
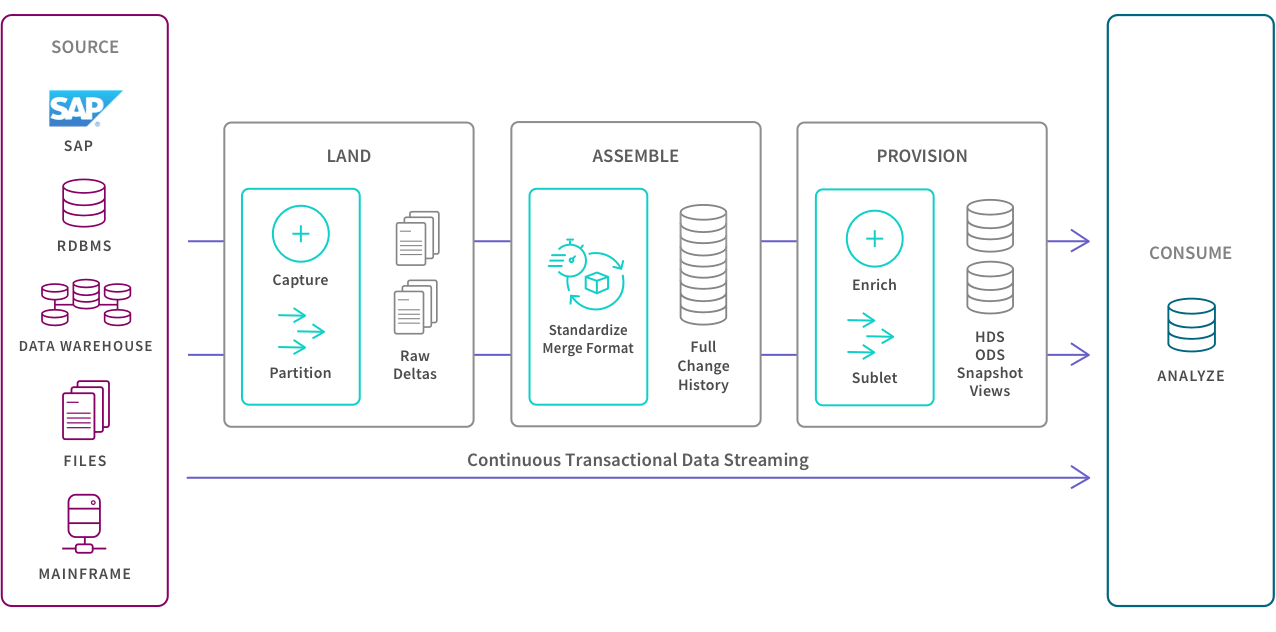
The illustration below shows where they sit within a modern data management process, transforming raw data into clean, business ready information.
This 2-minute video shows modern approaches to solving this challenge.

Below are the five primary approaches:
1. ETL
An ETL pipeline is a traditional type of data pipeline which converts raw data to match the target system via three steps: extract, transform and load. Data is transformed in a staging area before it is loaded into the target repository (typically a data warehouse). This allows for fast and accurate data analysis in the target system and is most appropriate for small datasets which require complex transformations.
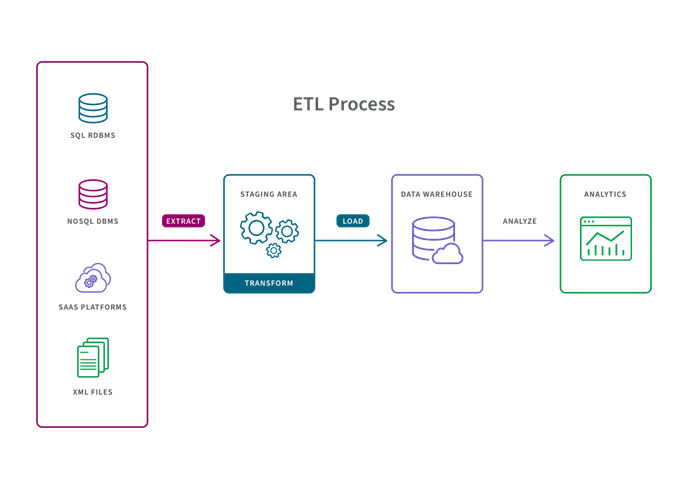
Change data capture (CDC) is a method of ETL and refers to the process or technology for identifying and capturing changes made to a database. These changes can then be applied to another data repository or made available in a format consumable by ETL, EAI, or other types of data integration tools.
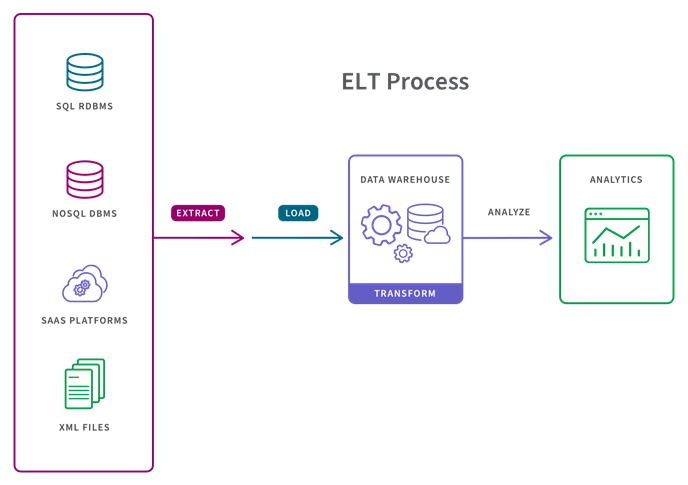
2. ELT
In the more modern ELT pipeline, the data is immediately loaded and then transformed within the target system, typically a cloud-based data lake, data warehouse or data lakehouse. This approach is more appropriate when datasets are large and timeliness is important, since loading is often quicker. ELT operates either on a micro-batch or (CDC) timescale. Micro-batch, or “delta load”, only loads the data modified since the last successful load. CDC on the other hand continually loads data as and when it changes on the source.
3. Data Streaming
Instead of loading data into a new repository in batches, streaming data integration moves data continuously in real-time from source to target. Modern data integration (DI) platforms can deliver analytics-ready data into streaming and cloud platforms, data warehouses, and data lakes.
4. Application Integration
Application integration (API) allows separate applications to work together by moving and syncing data between them. The most typical use case is to support operational needs such as ensuring that your HR system has the same data as your finance system. Therefore, the application integration must provide consistency between the data sets. Also, these various applications usually have unique APIs for giving and taking data so SaaS application automation tools can help you create and maintain native API integrations efficiently and at scale.
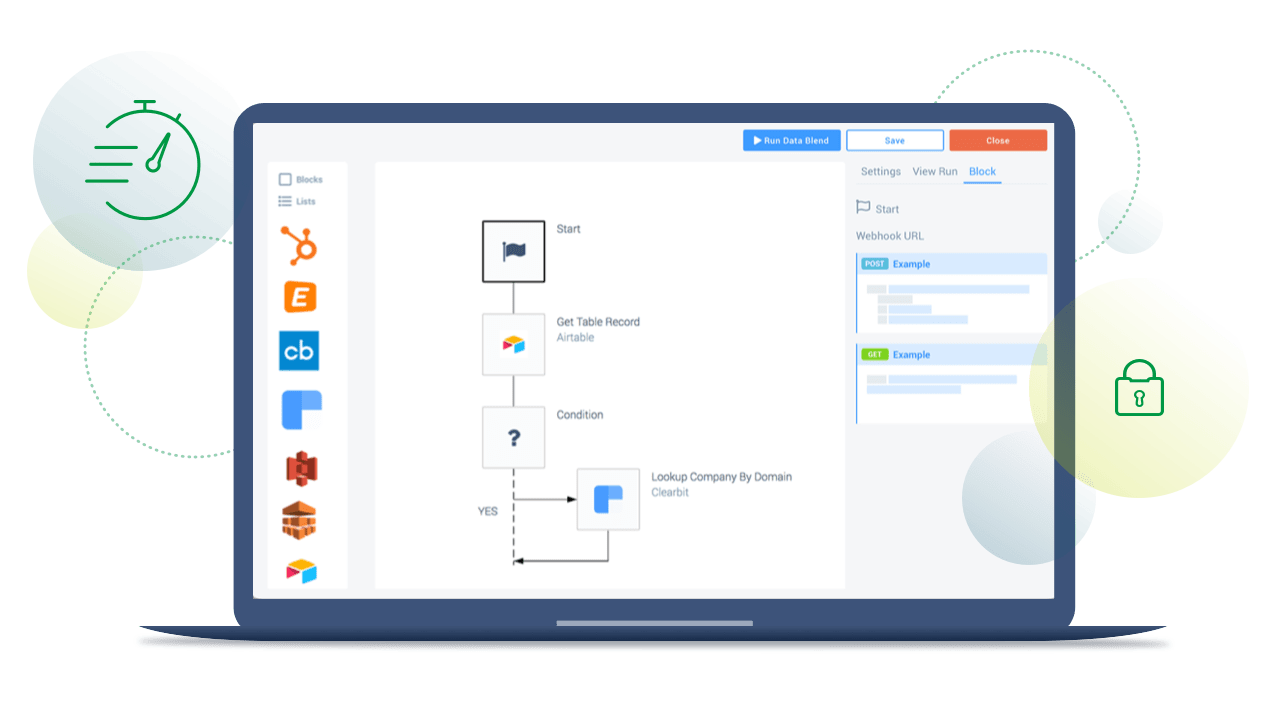
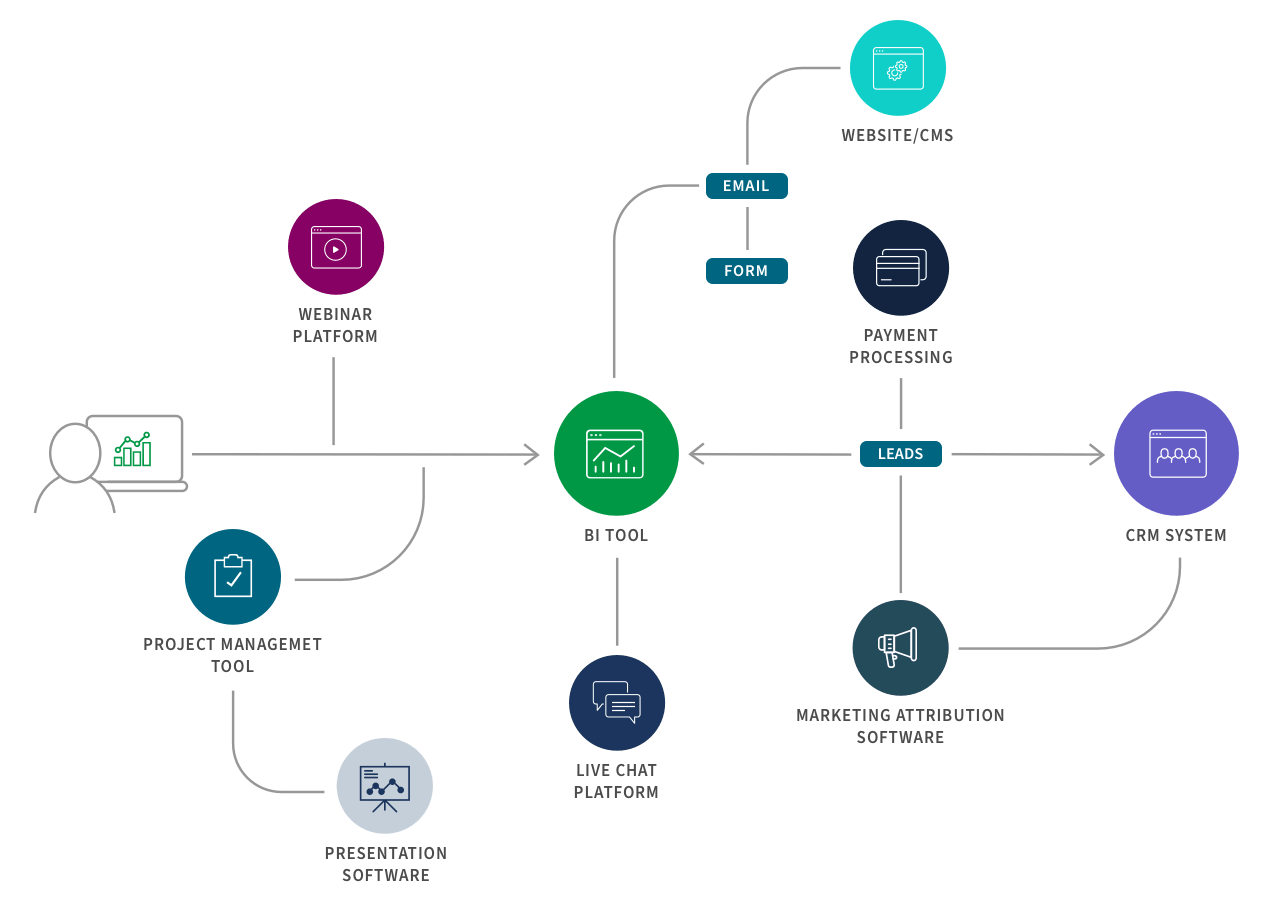
Here is an example of a B2B marketing integration flow:
5. Data Virtualization
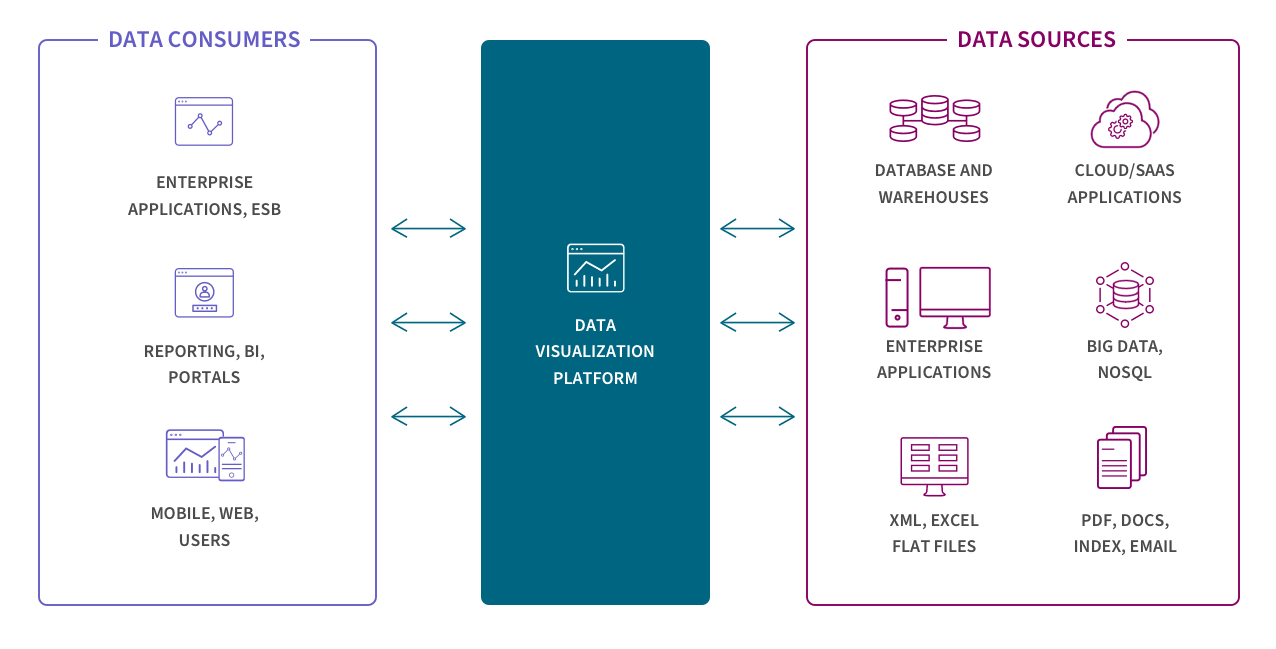
Like streaming, data virtualization also delivers data in real time, but only when it is requested by a user or application. Still, this can create a unified view of data and makes data available on demand by virtually combining data from different systems. Virtualization and streaming are well suited for transactional systems built for high performance queries.
Continually evolving
Each of these five approaches continue to evolve with the surrounding ecosystem of the modern data stack. Historically, data warehouses were the target repositories and therefore data had to be transformed before loading. This is the classic ETL data pipeline (Extract > Transform > Load) and it’s still appropriate for small datasets which require complex transformations.
However, with the rise of Integration Platform as a Service (iPaaS) solutions, larger datasets, data fabric and data mesh architectures, and the need to support real-time analytics and machine learning projects, integration is shifting from ETL to ELT, streaming and API.