






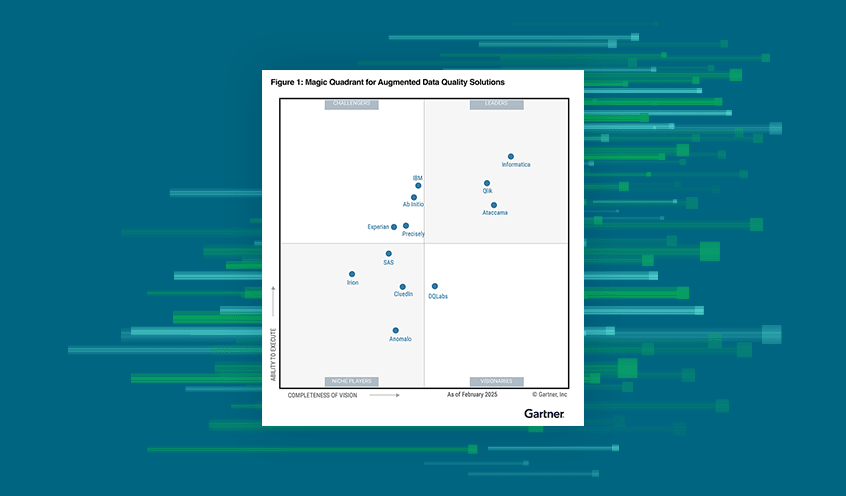






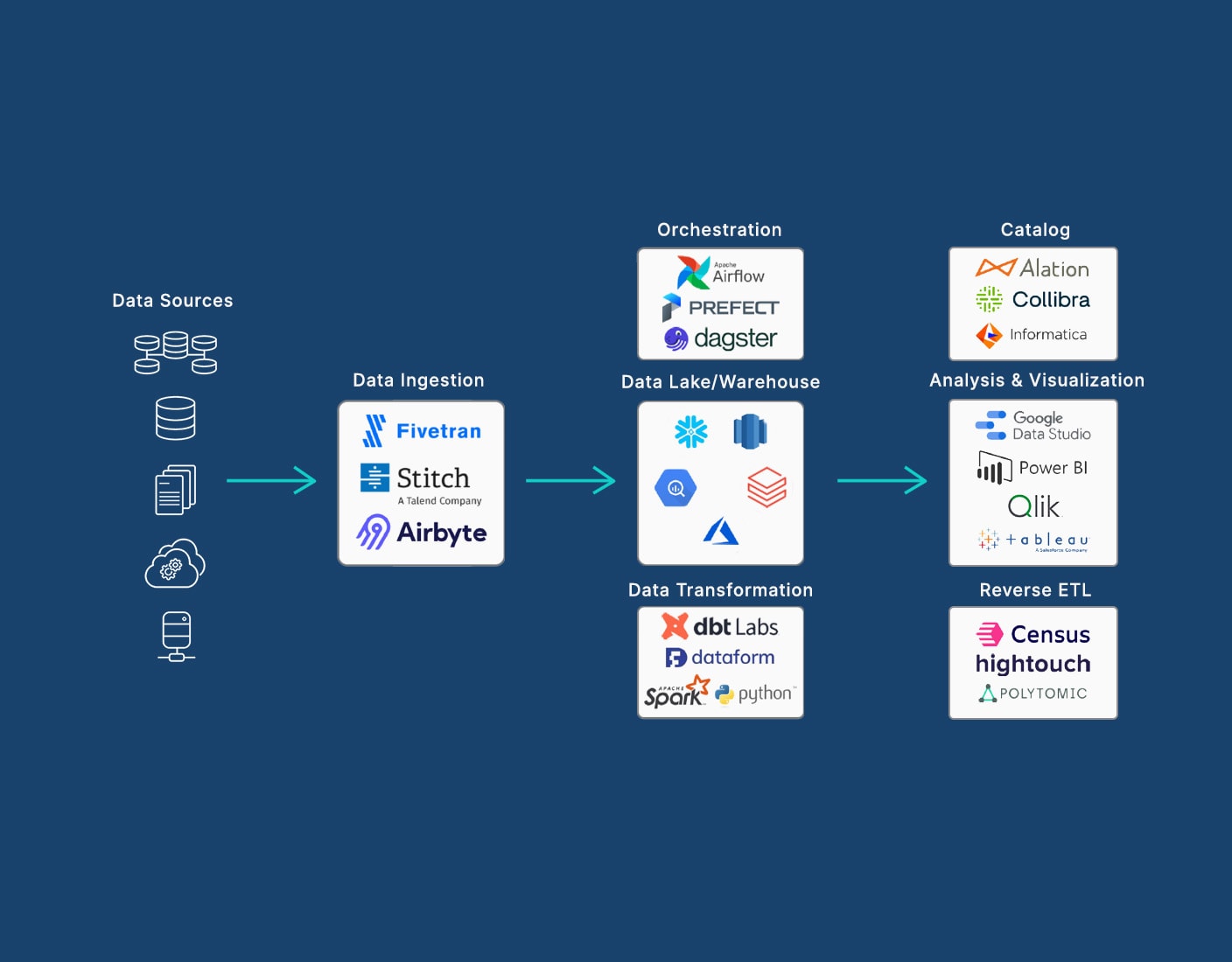
Main Functions
A modern data stack is a set of technologies used to collect, store, manage, and analyze data in modern, scalable ways.

Let’s delve into the 6 key components of the modern data stack and their functions, along with examples of top tools for each.
Data Sources
Function: Data sources are the origins of data, including databases, APIs, logs, and external services. They provide raw data that needs to be aggregated, ingested and processed.
What to Look For: Reliability, scalability, and compatibility with your existing infrastructure.
Top Tools:
SAP: Popular ERP software for businesses.
Google Analytics: A website tracking tool that provides user interaction insights.
Apache Kafka: A distributed event streaming platform.
Data Pipelines
Function: Data pipelines move and transform data from sources to destinations such as data warehouses or databases. They handle data ingestion, transformation, and loading processes (and reverse ETL).
What to Look For: Ease of use, fault tolerance, and support for various data formats.
Top Tools:
Fivetran: cloud-based automated data movement platform.
Qlik (which now includes Talend): Comprehensive ELT and ETL tools with visual interfaces.
Stitch: A simple cloud ETL service.
Data Storage
Function: Data storage solutions store processed data for querying and analysis. They include cloud data warehouses, data lakes, and databases.
What to Look For: Scalability, performance, and cost-effectiveness.
Top Tools:
Snowflake: A cloud data platform known for its elasticity and ease of use.
AWS Redshift: A powerful cloud data warehousing solution.
Databricks: A unified cloud platform for data, AI, and machine learning at scale.
Data Transformation
Function: Data transformation tools clean, enrich, and reshape data. They prepare it for analysis and reporting.
What to Look For: Flexibility, support for custom transformations, and integration capabilities.
Top Tools:
Trifacta (now Alteryx Designer Cloud): A user-friendly data wrangling platform.
dbt (Data Build Tool): An open-source, SQL-based transformation tool for ETL or ELT.
Matillion: An ETL platform designed for cloud data warehouses.
Data Analytics / Visualization
Function: Analytics tools allow users to explore and visualize big data, create business dashboards, and generate insights.
What to Look For: Intuitive interfaces, robust visualization options, and collaboration features.
Top Tools:
Qlik: An analytics platform with AI-powered insights and predictions.
Tableau: A powerful data visualization platform.
Power BI: Microsoft’s business intelligence tool.
Data Science/ML
Function: Data science and machine learning tools enable predictive modeling, classification, and anomaly detection.
What to Look For: Support for algorithms, scalability, and integration with other components.
Top Tools:
Python (with libraries like Pandas, NumPy, and Scikit-learn): Widely used programming language for data science and ML.
TensorFlow: An open-source ML framework by Google.
PyTorch: A popular deep learning library.
Remember that the modern data stack is dynamic, and new tools emerge regularly. Choose components that align with your data strategy, organizational needs, scalability requirements, and long-term goals.


