






Four Core Principles
The data architect Zhamak Dehghani first defined the term data mesh in 2019. The word “mesh” refers to the way in which domains can easily use data products from other domains and how data from multiple domains can be combined to get a more holistic view.
Dehghani based the approach on the four core principles described below. These principles enable scale and agility while also ensuring data quality and data integrity across your organization.
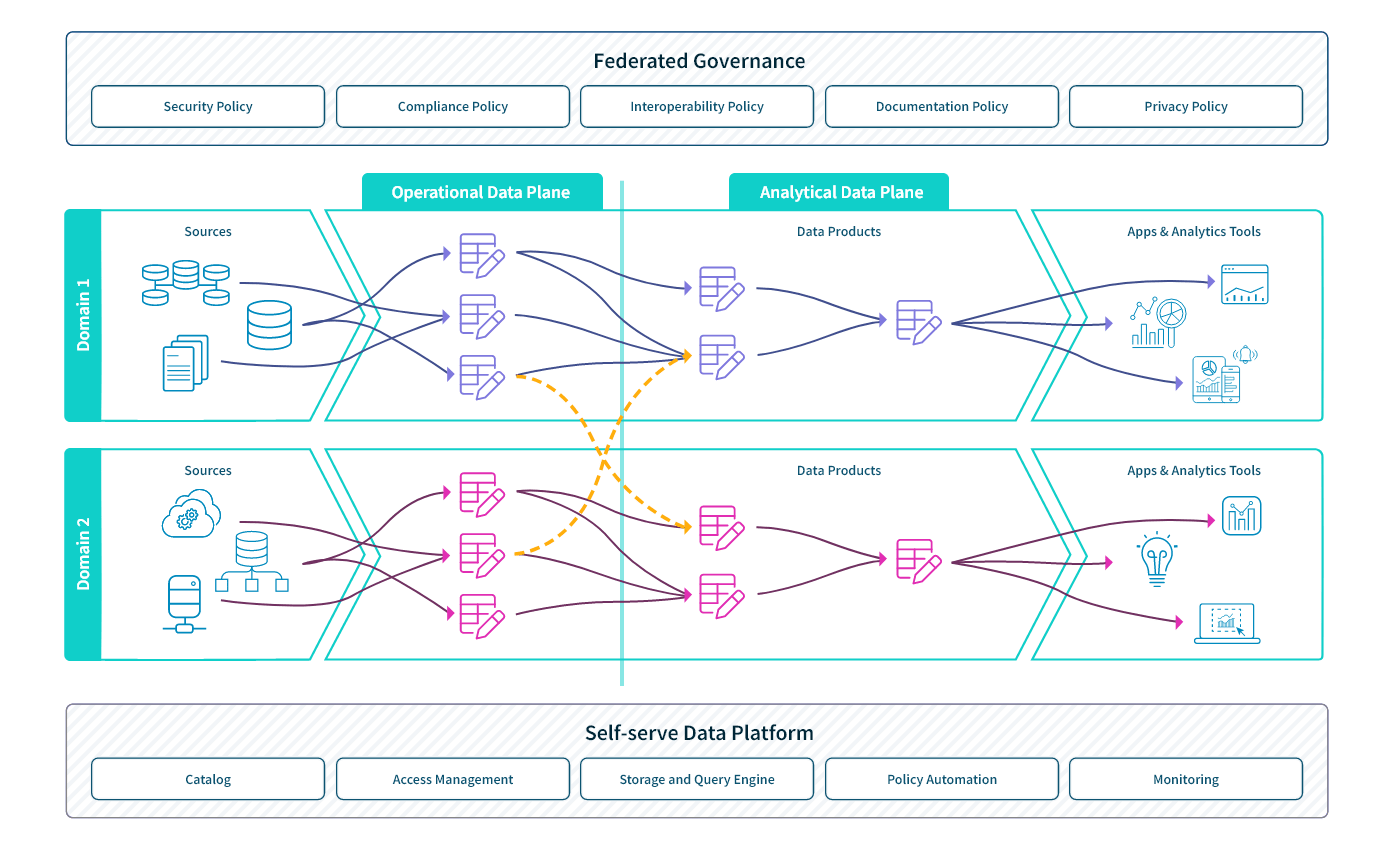
Domain-oriented, decentralized data ownership and architecture. This principle states that business domains such as customer service, operations, marketing, and sales develop, deploy, and manage their own analytical and operational data services. This allows each functional area to model their data based on their specific needs.
Data as a product. This principle requires the domain teams to think of other domains in your organization as consumers and to support their needs. This means ensuring high-quality, secure, up-to-date data.
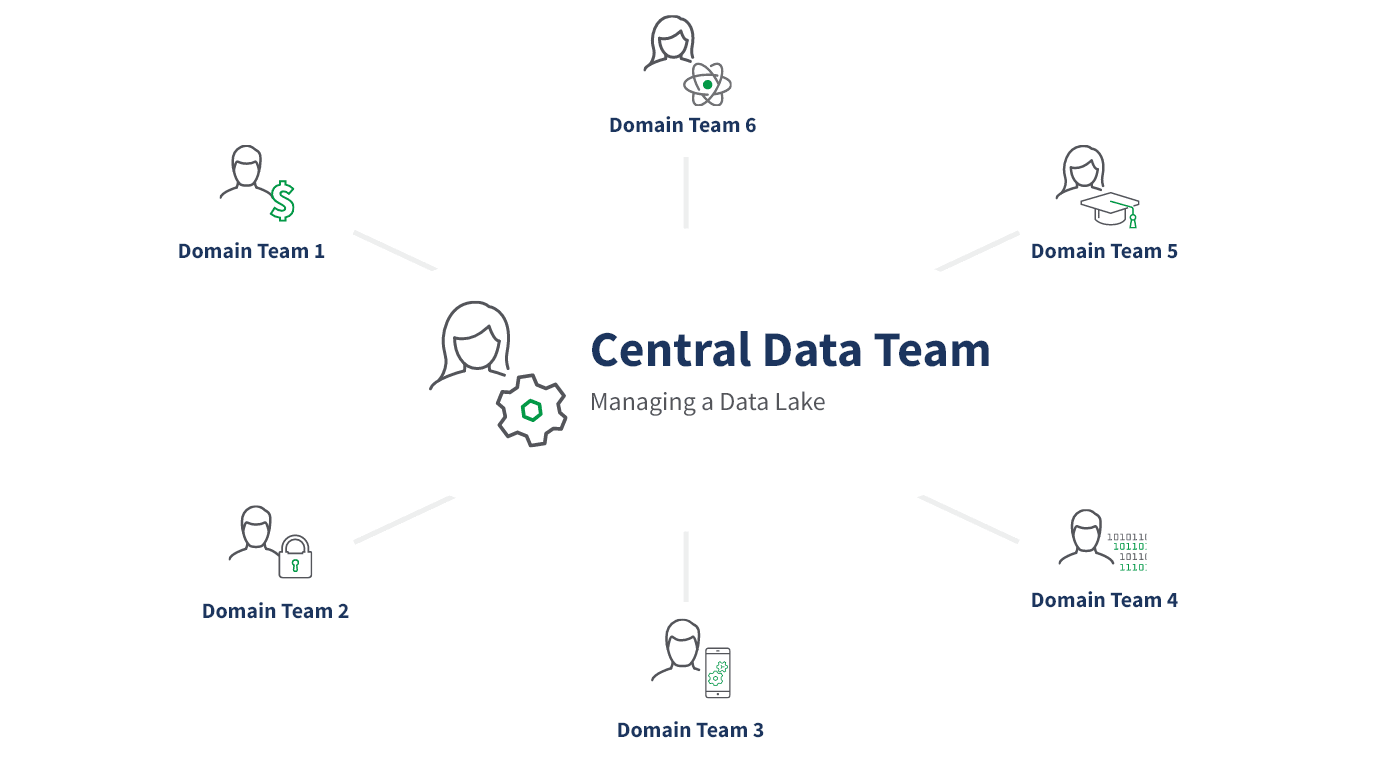
Self-service data infrastructure as a platform. According to this principle, your organization should have a dedicated infrastructure engineering team that provides the tools and systems for each domain team to consume data from other domains and to autonomously develop, deploy, and manage data products that are interoperable across all domains.
Federated computational governance. This principle states that while you must have a centralized data governance authority, you should also embed governance issues within the processes of each domain. This way, each domain has autonomy and can move quickly while also adhering to organizational and governmental rules.