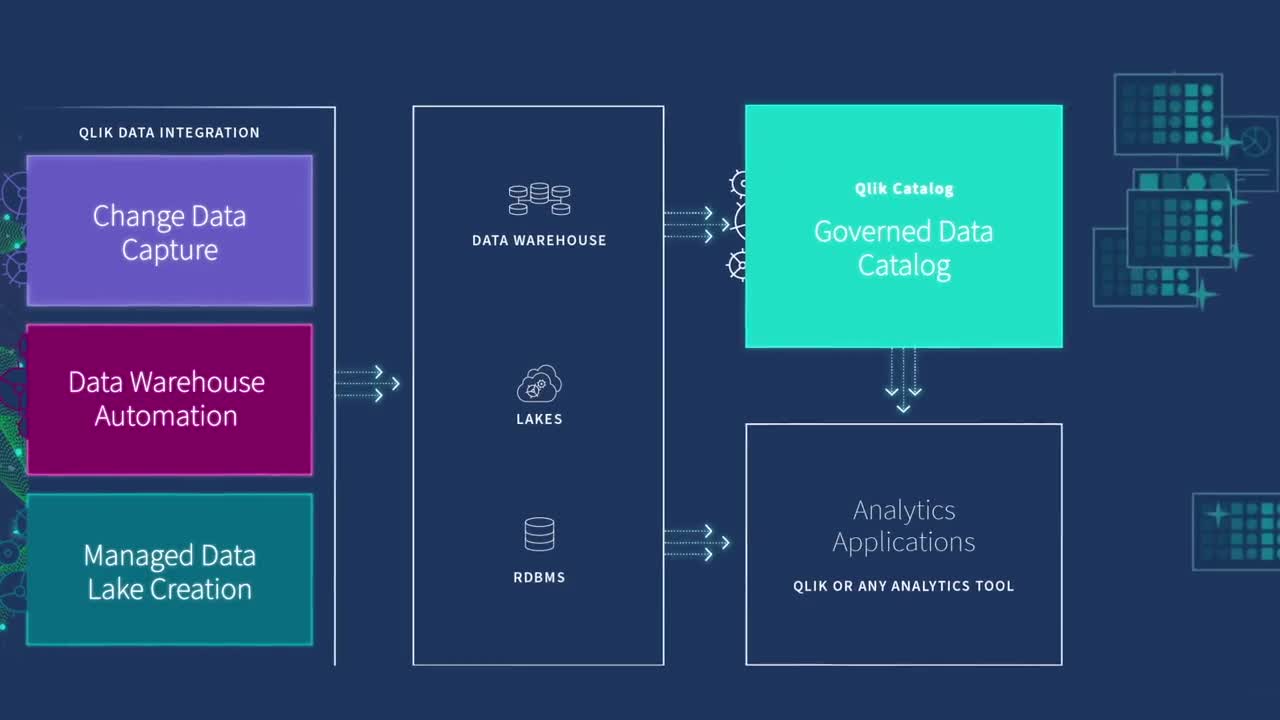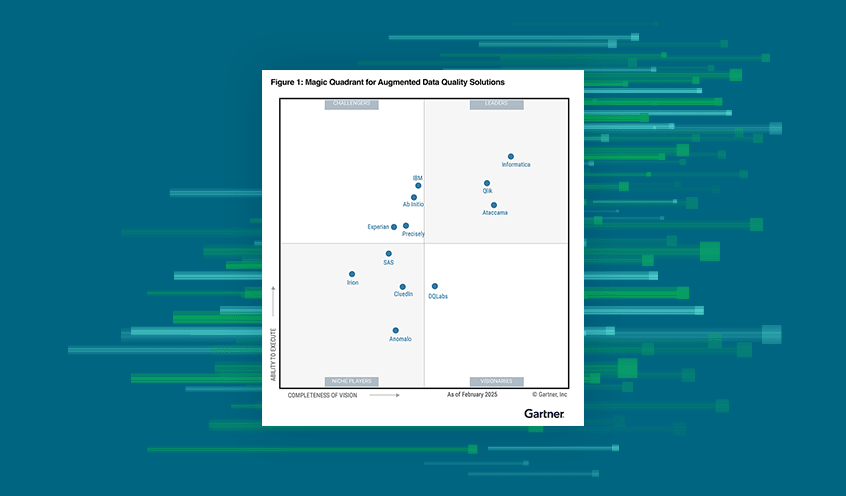






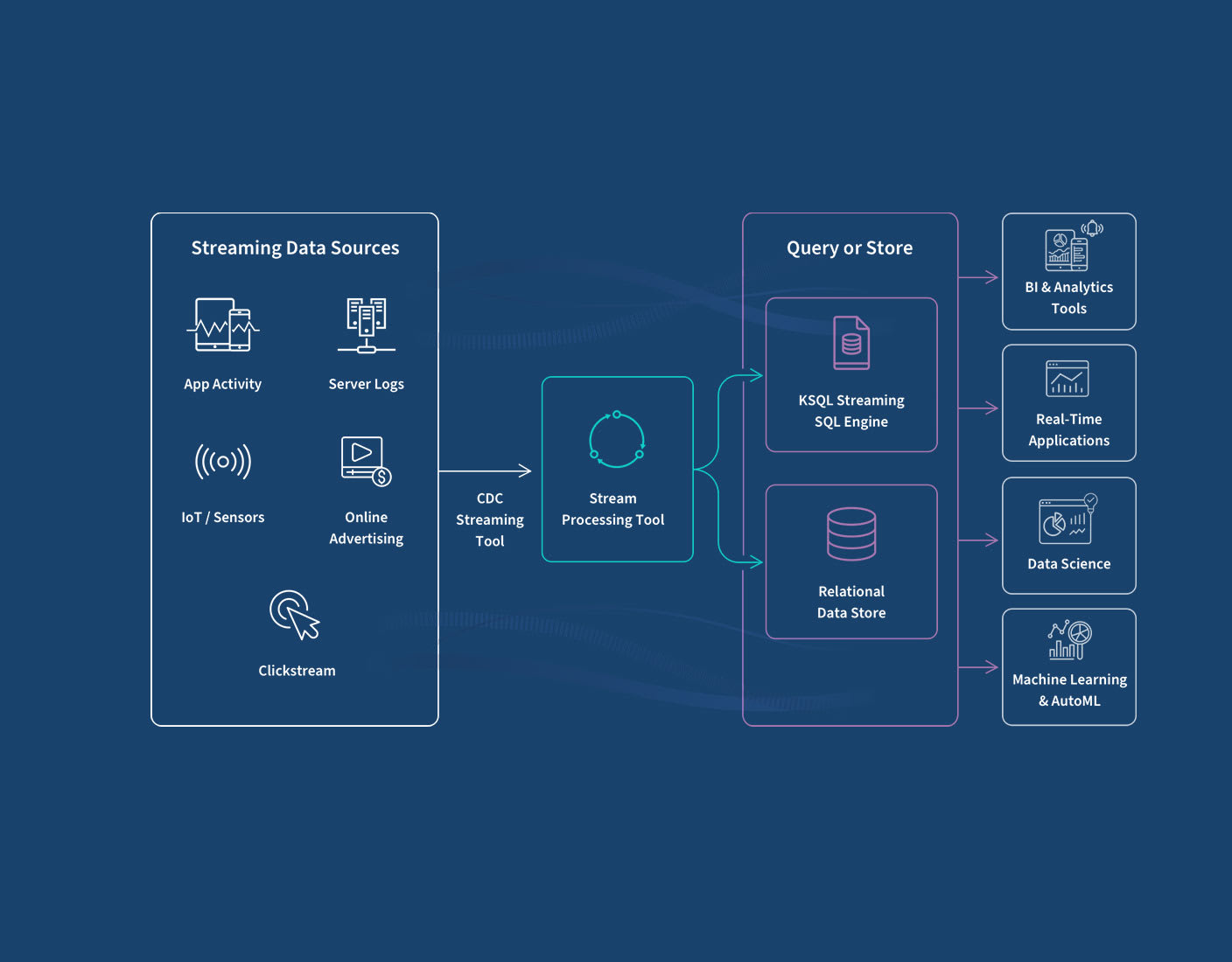
How It Works
Streaming data involves real-time processing of data from up to thousands of sources such as sensors, financial trading floor transactions, e-commerce purchases, web and mobile applications, social networks and many more.
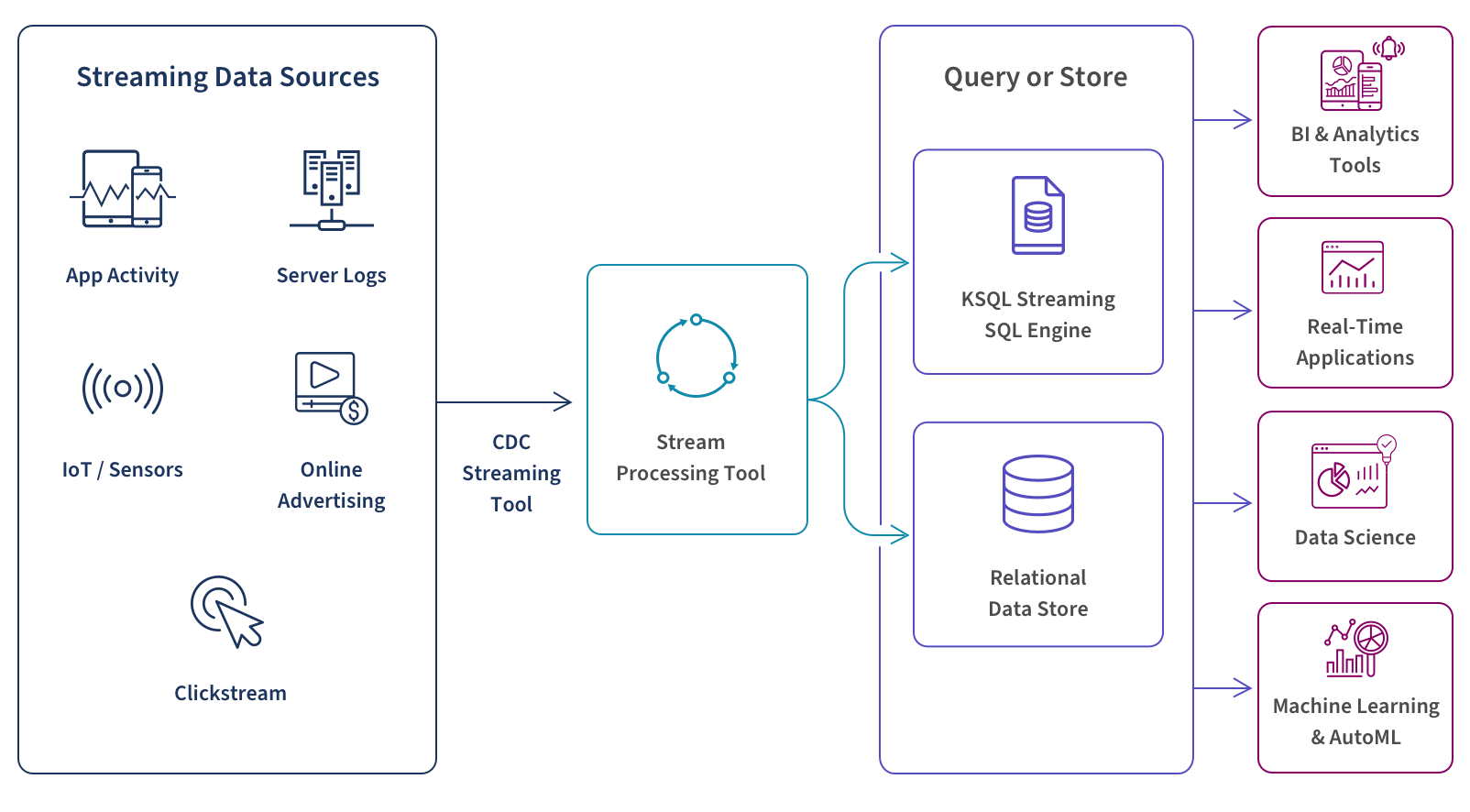
You can choose to perform real-time queries, store your data, or both. At this stage, your streaming database infrastructure must filter, aggregate, correlate, and sample your data using tools such as Google BigQuery, Snowflake, Dataflow, or Amazon Kinesis Data Analytics. To query the real-time data stream itself, you can use a streaming SQL engine for Apache Kafka called ksqlDB. To store this data in the cloud for future use you can use a streaming database or cloud data warehouse such as Amazon S3, Amazon Redshift, or Google Storage.
Finally, by aggregating and analyzing these real-time data streams, you can use real-time analytics to trigger downstreaming applications, gain in-the-moment business insights, make better-informed decisions, fine-tune operations, improve customer service and act quickly to take advantage of business opportunities.