












Data Integration
Understanding Data Lakehouses: A Modern Data Management Approach


What is a Data Lakehouse?
Historically, organizations faced a dilemma—data lakes offered cost-effective, scalable storage for unstructured and semi-structured data but lacked performance optimization, while data warehouses provided structured data management but were expensive and rigid. Data lakehouses solve this problem by seamlessly integrating these two models, allowing businesses to store, manage, and analyze data without compromise.
Why Data Lakehouses Matter: Key Features & Benefits
1. Unified Data Management
Lakehouses eliminate data silos by providing a centralized platform that supports multiple use cases, from AI & machine learning and business intelligence to advanced analytics—all within a single system. This reduces redundancy, improves efficiency, and simplifies data management.
2. Handling Diverse Data Types
Unlike data warehouses, which primarily manage structured data, lakehouses can efficiently store and process structured, semi-structured (JSON, XML), and unstructured data (videos, images, logs, IoT data). This enables businesses to work with richer and broader datasets.
3. Built on Open Standards
Data lakehouses leverage open file formats such as Apache Parquet, Avro, and ORC, along with open table formats like Apache Iceberg, Hudi, and Delta Table. This ensures interoperability across platforms and eliminates vendor lock-in.
4. Decoupled Storage and Compute
By separating storage from compute, lakehouses allow organizations to optimize costs by using affordable cloud object storage while choosing the best processing engine for their needs. This provides greater flexibility and scalability.
5. Real-Time and Batch Processing
Unlike traditional architectures that require separate infrastructures for batch and real-time data processing, lakehouses unify both, enabling businesses to gain insights from live streaming data while also maintaining historical analysis capabilities.
6. Transactional Integrity with ACID Compliance
One of the major challenges of data lakes has been ensuring data consistency. Lakehouses overcome this by supporting ACID (Atomicity, Consistency, Isolation, Durability) transactions, allowing multiple users to access and update data simultaneously without compromising integrity.
7. Advanced Governance & Security
Strong governance and security controls allow businesses to manage access, track data lineage, and ensure compliance with industry regulations—all from a single control plane.
Comparing Data Lakehouses with Traditional Data Architectures
Feature | Data Warehouse | Data Lake | Data Lakehouse |
|---|---|---|---|
Data Type | Structured | Structured & Unstructured | Structured & Unstructured |
Data Format | Proprietary | Open | Open |
Cost Efficiency | High | Low | Low |
Performance | High | Low | High |
Governance & Security | Strong | Weak | Strong |
Scalability | High | High | High |
Streaming Support | High | Yes | Yes |
The Rise of Open Lakehouses
Open lakehouses represent a shift toward fully interoperable data ecosystems. Unlike proprietary solutions, they are built on open standards and open-source technologies, ensuring that businesses have greater flexibility in choosing analytics tools and processing engines. Open lakehouses utilize open file formats (Parquet, ORC, Avro) and table formats (Apache Iceberg, Hudi, Delta Table) to maximize compatibility.
Why Open Lakehouses Matter:
Eliminate vendor lock-in by using open standards.
Enable seamless collaboration across teams and platforms.
Optimize compute and storage independently for cost-effective scaling.
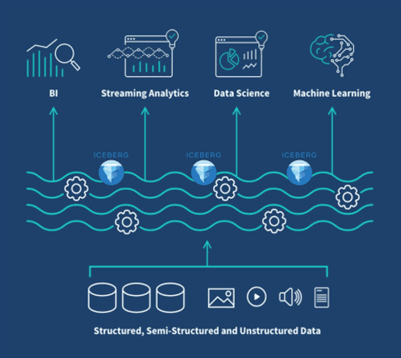
Apache Iceberg: The Backbone of Modern Lakehouses

As an Apache project, Iceberg is 100% open source and not dependent on any individual tools or data lake engines. It was created by Netflix and Apple and is deployed in production by the largest technology companies and proven at scale on the world’s largest workloads and environments.
More importantly, Iceberg is optimized for handling both batch and streaming data and offers the flexibility and interoperability that businesses demand. It enables users store data cost effectively in any of the Cloud storage engines (Amazon S3, Microsoft ADLS, Google Cloud Storage etc) and query data using any of the processing/ query engines like Snowflake, Databricks, Apache Spark, Dremio, Flink, Presto, Trino, Amazon Athena and more...
Key Capabilities of Apache Iceberg:
ACID Transactions: Ensures consistency and reliability for concurrent data reads and writes.
Time Travel & Versioning: Allows users to access historical data snapshots for audits and rollbacks.
Schema Evolution: Supports schema updates without the need for disruptive data migrations.
Partitioning Optimization: Enhances query performance by automatically optimizing partitions.
Multi-Engine Compatibility: Works seamlessly with Apache Spark, Trino, Presto, Flink, and Hive.
By integrating Apache Iceberg, businesses can harness a scalable, high-performance solution for managing complex datasets in their lakehouse environments.
Why Organizations Are Adopting Data Lakehouses
Businesses across industries are rapidly adopting data lakehouses due to their ability to:
Reduce costs by eliminating data duplication and optimizing storage.
Unify analytics by combining real-time and historical data insights.
Enhance data governance with fine-grained security and compliance features.
Foster AI and machine learning by enabling seamless data access across teams.
Final Thoughts
The data lakehouse represents a fundamental shift in data management, blending the best aspects of lakes and warehouses while leveraging open technologies for enhanced flexibility. As businesses generate and consume data at an unprecedented scale, lakehouses offer a future-proof solution for analytics, AI, and real-time decision-making. Organizations that embrace this architecture will be well-positioned to drive innovation and unlock new opportunities in the data-driven world.
Learn More:
Join us for Qlik Connect 2025 on May 13-15th for compelling sessions and in-depth insights on Open Lakehouses and how to build using Apache Iceberg.
Here are some of the key sessions you don’t want to miss.
Iceberg Ahead: Build an Open Lakehouse with Qlik Talend Cloud and Apache Iceberg
Revolutionizing Iceberg Ingestion: Qlik Talend® and Upsolver in Action
Workshop Apache Iceberg: Unleash the Power of the Open Lakehouse Table Format
Unleash the Power of Apache Iceberg: Building Your AI and Analytics platform with Qlik Cloud® on AWS

In this article:
Data Integration